Game From Zero: Part 2. 'Memory'
Progress on developing a 2D game from scratch.
I recommend reading my previous post, “Game From Zero: Part 1. ‘Drawing’”.

How memory is allocated can have a great impact on performance and how badly memory is fragmented on a game. Different subsystems of the game allocate memory in a different way. My game is quite simple so I won’t go crazy on implementing a large amount of allocators. I’ll only implement three simple solutions. The first one will wrap around the OS virtual memory allocator. The second one will be a linear or scratch allocator. The last one will be a pool allocator. Each approach can be used to solve different problems. One of the main problems I’ll try to solve here is fragmentation.
Fragmentation
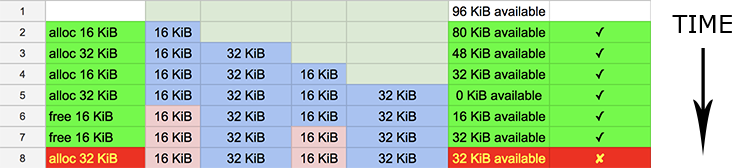
When I talk about memory fragmentation I talk about having enough memory to do an allocation, but chunks are not contiguous, therefor the allocation can’t happen. This will throw an error or some kind of “out of memory” exception.
You can observe in the image how through time we add holes in to our memory region. In this case we leave two chunks of 16 KiB free. If we try to allocate 32 KiB, the process fails even though there is enough memory to handle that allocation.
This problem can appear if the game is constantly allocating and deallocating different chunks of memory. Eventually a bad allocation pattern could lead to running out of memory.
Virtual Memory
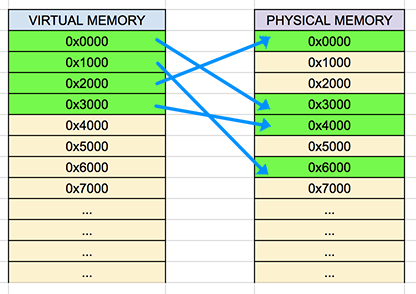
Before implementing any other solution we need a way of allocation memory from OS. This means implementing a platform specific solution. The good thing about this is that most OS provide a way of allocating virtual memory.
By virtual memory I mean virtual addresses that map to physical memory. The OS keeps lookup tables called page tables that help translate virtual addresses to physical addresses. This means that when I allocate virtual memory I’ll be allocating pages of memory and not individual bytes as you would with solutions like malloc. It’s important to mention that malloc internally uses virtual memory allocation an then portions it. This is the same approach I’ll use for my allocators.
Page Allocation on Darwin
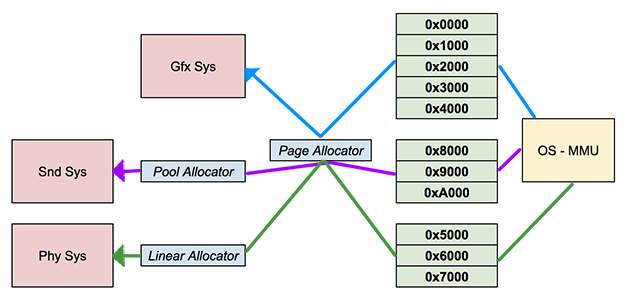
The main memory allocator in my game is called “page allocator”. The page allocator isn’t like the other allocators, since it’s just a wrapper over a kernel function. How pages are allocated depends on the OS. This allocator interfaces with the OS to acquire pages that are then distributed to specific game systems. Each system can either use the pages directly or use other allocators to manage their associated region.
As I mentioned on my previous post, I am using a MacBook Pro to develop this game and I am currently building it for iOS and TvOS. A nice thing about this is that all three systems share the same OS which is called Darwin.
The function that Darwin provides for us to handle virtual memory allocation is vm_allocate. This function will tell the kernel to allocate the required region. Here you can read in detail what vm_allocate does and what parameters it needs. Another useful function to use is host_page_size. This function returns the OS’s page size.
My page allocator function is very simple. Here is the platform angostic interface.
// memory.h
typedef struct {
void* pAddress;
size_t size;
} PageAllocation;
bool32_t mem_page_alloc(size_t size, PageAllocation* pAllocationInfo);
bool32_t mem_page_free(const PageAllocation* pAllocationInfo);This is the Darwin implementation.
// memory_Darwin.c
bool32_t mem_page_alloc(size_t size, PageAllocation* pAllocationInfo) {
vm_address_t address = 0;
vm_size_t pageSize = round_page(size);
kern_return_t result = KERN_SUCCESS;
result = vm_allocate(mach_task_self(), &address, pageSize, VM_FLAGS_ANYWHERE);
if (result != KERN_SUCCESS) return UT_FALSE;
pAllocationInfo->pAddress = (void*)address;
pAllocationInfo->size = pageSize;
return UT_TRUE;
}
bool32_t mem_page_free(const PageAllocation* pAllocationInfo) {
kern_return_t result = KERN_SUCCESS;
result = vm_deallocate(mach_task_self(), (vm_address_t)pAllocationInfo->pAddress, (vm_size_t)pAllocationInfo->size);
if (result != KERN_SUCCESS) return UT_FALSE;
return UT_TRUE;
}In this case vm_allocate makes it very easy for me. The last flag value just tells the function that I don’t care about the address, I just want the region of memory. The equivalent of vm_allocate on Windows is VirtualAlloc. This is good to know for when I implement that part of the code at some point.
One functionality I could add in the future that would be very useful for debugging is page protection. Just as there is vm_allocate and vm_deallocate we have vm_protect. This function allows me to set the access privileges for a region of memory. This could be useful for implementing guards to detect r/w overflows.
Linear Allocator

The easiest solution for managing a memory region has to be using a buffer and a mechanism that bumps a pointer for each allocation. This approach is generally known as a linear allocator.
A big advantage about this design is that it’s very fast and easy to implement. It is perfect as a scratch buffer that is reset after a period of time. In this game I’ll mostly use the linear allocator for frame allocation that is discarded at the end of the frame.
One situation I am currently using it for is for generating quadtrees at runtime. Since the quadtree is not used after the frame ends, I can easily reset the buffer and not fear accessing dangling pointers.
For my implementation I wanted to have a solution where I can swap which buffer I am using. For example, I might use a scratch buffer for quadtrees and another for physics. This is why I use something I call context. Context just store the original page allocation, a pointer for the start of the buffer, a pointer indicating the current position in the buffer and how much is used in bytes by the buffer.
This is how the interface of the linear allocator looks like.
// memory.h
typedef struct _LinearContext {
PageAllocation pageAlloc;
void* pHead;
void* pCurr;
size_t usedByteSize;
} MemLinearContext;
void mem_linear_set_context(MemLinearContext* pContext);
void mem_linear_set_default_context(void);
void* mem_linear_alloc(size_t size, uint32_t alignment);
void mem_linear_reset(void);The implementation for mem_linear_alloc is quite simple. First I check if the context has enough space. Then I align the pointer pCurr by alignment and save it as the return address. After that I increment the pointer pCurr by size and return the final address.
// memory.c
void* mem_linear_alloc(size_t size, uint32_t alignment) {
alignment = alignment < MEM_DEFAULT_ALIGNMENT ? MEM_DEFAULT_ALIGNMENT : alignment;
void* p = UT_ALIGN_POINTER(pCurrentLinearContext->pCurr, alignment);
if (UT_IN_RANGE(UT_FORWARD_POINTER(p, size), pCurrentLinearContext->pHead, UT_FORWARD_POINTER(pCurrentLinearContext->pHead, kMemLinearContextCapacity))) {
pCurrentLinearContext->pCurr = UT_FORWARD_POINTER(p, size);
pCurrentLinearContext->usedByteSize += size;
#if defined(_DEBUG)
memset(p, 0xAA, size);
#endif
return p;
}
return NULL;
}One thing I only do on the debug build is fill the buffer with the tag value 0xAA.
The function mem_linear_reset is just setting the pointer pCurr to pHead invalidating every block of memory allocated with this context.
// memory.c
void mem_linear_reset() {
#if defined(_DEBUG)
if (pCurrentLinearContext->usedByteSize > 0)
memset(pCurrentLinearContext->pHead, 0xDD, pCurrentLinearContext->usedByteSize);
#endif
pCurrentLinearContext->usedByteSize = 0;
pCurrentLinearContext->pCurr = pCurrentLinearContext->pHead;
}Pool Allocator
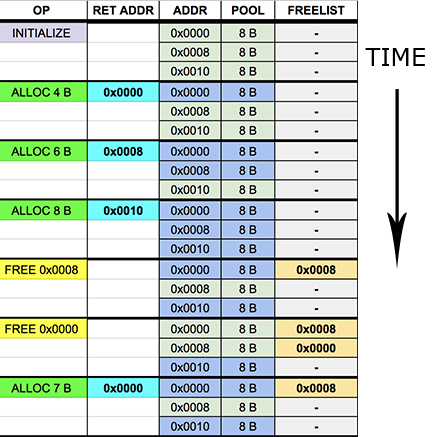
For the imeplementation of my pool allocator I took some ideas from a traditional pool allocator and buddy allocator. What I did was partition the main allocated buffer into sections of up to 1024 bytes starting from 8 bytes. Each partition is called a pool, each pool is associated with a fixed size of power of two. Instead of using a free list for keeping track of free regions of memory I just use a free stack. Since pools represent fixed size blocks it doesn’t matter which block I choose on the stack because all of them will have the same size.
The interface for my pool allocator looks like this.
// memory.h
typedef struct {
PageAllocation pageAlloc;
void** pAddresses;
size_t capacity;
size_t count;
} MemAddrStack;
typedef struct {
MemAddrStack freeStack;
PageAllocation pageAlloc;
void* pHead;
void* pCurr;
size_t elementSize;
size_t usedByteSize;
} MemPool;
typedef struct {
MemPool pools[POOL_COUNT];
} MemPoolContext;
void* mem_pool_alloc(size_t size);
void mem_pool_free(void* p);I decided to keep the free information and the allocated chunks separated. This way the allocated blocks are tightly packed and I can avoid stomping on the header information.
MemAddrStack is just a simple stack of pointers. MemPool is the structure that holds the information of the pool. MemPoolContext is just an array of MemPools.
During mem_pool_alloc I round up the requested size to the closest power of two value. With this value I can know which pool to use for this allocation. If the pool has elements on the free stack, I pop the stack and return the address that was on the top of it. If the stack is empty I just bump the current buffer pointer by the pool element size and return the address. In a sense this is similar to the linear allocator, but with fixed size blocks.
// memory.c
void* mem_pool_alloc(size_t size) {
if (size < kPoolSizes[0]) size = kPoolSizes[0];
UT_ROUND_POT(size);
if (size <= kPoolSizes[POOL_COUNT - 1]) {
uint32_t poolIndex = 0;
if (size < kPoolSizes[POOL_COUNT / 2]) {
for (poolIndex = 0; poolIndex < POOL_COUNT; ++poolIndex) {
if (size == kPoolSizes[poolIndex]) break;
}
} else {
for (poolIndex = POOL_COUNT - 1; poolIndex >= 0; --poolIndex) {
if (size == kPoolSizes[poolIndex]) break;
}
}
MemPool* pPool = &gMemPoolContext.pools[poolIndex];
if (pPool->freeStack.count > 0) {
void* pFreeAddress = pPool->freeStack.pAddresses[--pPool->freeStack.count];
return pFreeAddress;
}
void* pNewAddress = pPool->pCurr;
void* pNextAddress = UT_FORWARD_POINTER(pNewAddress, size);
if (UT_IN_RANGE(pNextAddress, pPool->pHead, UT_FORWARD_POINTER(pPool->pHead, pPool->pageAlloc.size))) {
pPool->pCurr = pNextAddress;
pPool->usedByteSize += size;
#if defined(_DEBUG)
memset(pNewAddress, 0xAA, size);
#endif
return pNewAddress;
}
}
return NULL;
}During the mem_pool_free function I just iterate through all pools and check if the pointer is in the region associated with the pool. If it is then I proceed to add the pointer to the free stack. If the pointer doesn’t belong to any pool I just throw a software panic and stop the execution of the program.
void mem_pool_free(void* p) {
for (uint32_t index = 0; index < POOL_COUNT; ++index) {
MemPool* pPool = &gMemPoolContext.pools[index];
void* pHead = pPool->pHead;
if (UT_IN_RANGE(p, pHead, UT_FORWARD_POINTER(pHead, pPool->pageAlloc.size))) {
pPool->freeStack.pAddresses[pPool->freeStack.count++] = p;
pPool->usedByteSize -= pPool->elementSize;
#if defined(_DEBUG)
memset(p, 0xDD, pPool->elementSize);
#endif
return;
}
}
DBG_PANIC("Trying de free memory that doesn't belong to any pool on the current context");
}The biggest benefit of this solution is that we can have very low fragmentation over the whole region and generally blocks will be packed contiguously.
One of the main problems that this solution has is internal fragmentation. This means if you allocate a block of 513 bytes you’ll get a block of 1024 bytes and almost half of that block will be unused.
Final Note
One thing to have in mind is that I used these solutions because my game is very simple and small. I don’t need very complex-thread-safe-lock-free solutions. Most of the game will happen on a single thread and the code will be executed sequentially. I am sure these solutions could be implemented using thread local storage to allow per thread allocation. I imagine that would be a fun thing to look into in the future.